如何让Agent长出自己的眼和手
一个会说但不会做的助手
你有没有遇到过这种情况:你问 AI 一个问题,它给你一段完美的回答,但你需要自己去执行每一步。
“帮我把这个 bug 修了。”
它会告诉你:打开某个文件,找到第 42 行,把 foo 改成 bar,然后运行 npm test 验证。
说得头头是道。但它自己不动手。
这就像你雇了一个顾问,他坐在旁边指点江山,但从来不碰键盘。你得自己打开编辑器、找到那一行、改完、跑测试、看结果、再回来告诉他”改完了,但测试还是挂了”。然后他再给你下一步建议。
来回折腾几次,你就会想:你能不能自己来?
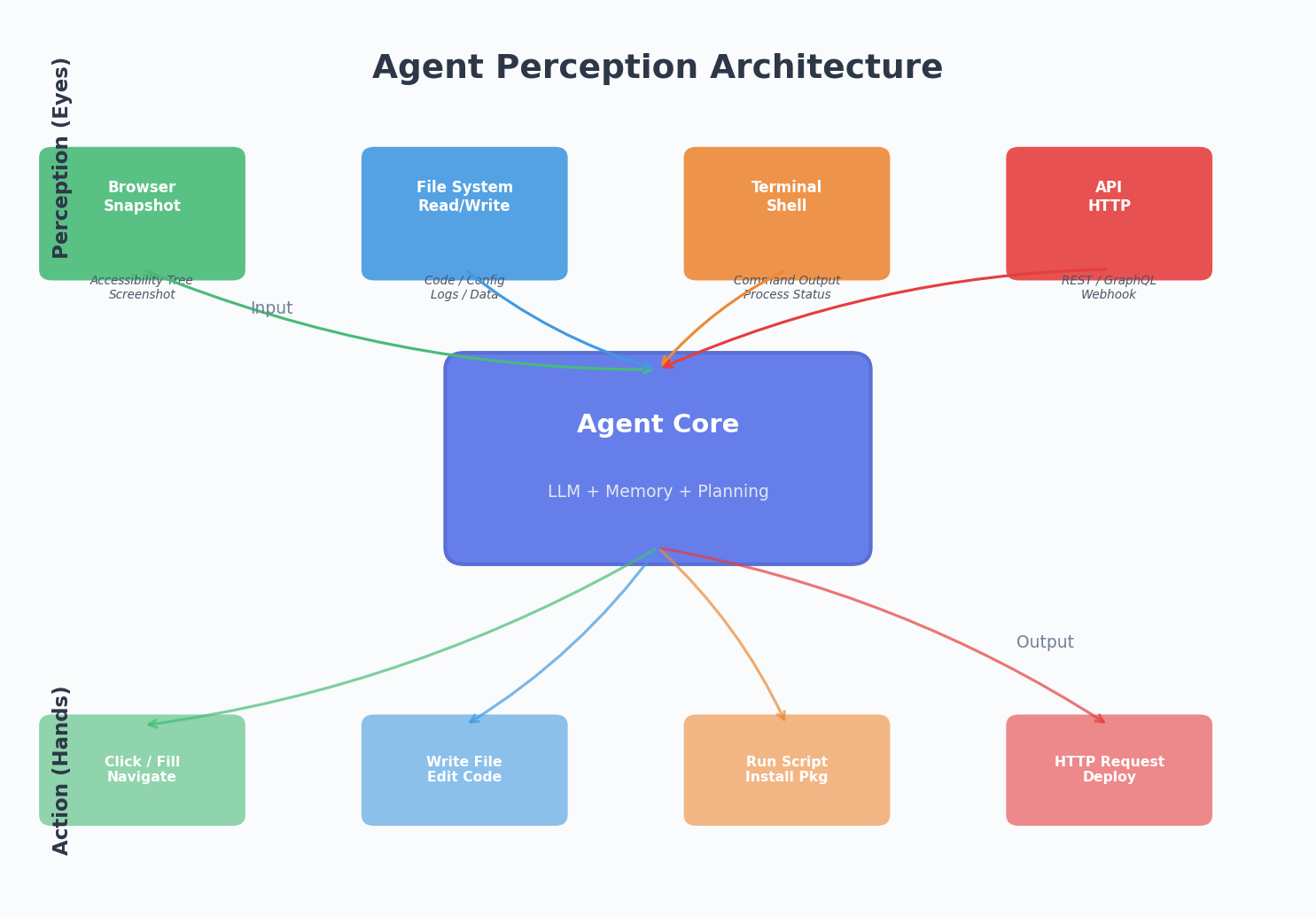
这就是为什么 Agent 需要”眼”和”手”——不只是语言能力,还需要感知世界的能力和改变世界的能力。
眼:让 Agent 看见世界
一个没有感知能力的 Agent,就像一个蒙着眼睛的人。你得不停地口述周围的环境,它才能给出建议。效率极低,而且你描述的信息永远是有损的。
浏览器就是 Agent 的眼睛
我最近的实践中,给 Agent 接入了一个浏览器工具。它能做什么呢?
- 打开网页:直接访问 URL,看到页面内容
- 获取快照(Snapshot):拿到页面的 accessibility tree——一种结构化的页面描述,比截图更适合 AI 理解
- 截图:当需要视觉判断时,直接截取屏幕画面
- 执行 JavaScript:在页面上下文中运行代码,获取 DOM 信息或触发操作
这里面最关键的是 Snapshot。
很多人第一反应是给 Agent 截图,让多模态模型”看”图片。这当然可以,但效率很低——一张截图可能要消耗几千 token,而且模型从图片中提取结构化信息的准确率远不如直接读结构化数据。
Accessibility tree 是浏览器为无障碍功能维护的一棵树,它描述了页面上每个可交互元素的角色、名称和状态。对 Agent 来说,这就是一张”语义地图”——它不需要知道按钮是什么颜色、在屏幕哪个位置,它只需要知道”这里有一个叫’提交’的按钮,ref 是 e42”。
Snapshot 是 AI 友好的,截图是人类友好的。 给 Agent 用 Snapshot,给人类看截图。
不只是浏览器
眼睛不只是浏览器。Agent 的感知能力可以扩展到很多维度:
- 文件系统:读取代码文件、配置文件、日志文件
- 终端输出:执行命令后看到 stdout 和 stderr
- API 响应:调用接口后解析返回数据
- Git 状态:知道当前分支、未提交的改动、最近的 commit
每一种感知通道都在告诉 Agent:世界现在是什么样子的。
手:让 Agent 改变世界
光看不够,还得能动手。
脚本执行是最通用的”手”
如果只能给 Agent 一种行动能力,我会选执行 shell 脚本。
为什么?因为 shell 是万能胶水。你能用它:
- 创建、修改、删除文件
- 安装依赖、运行构建、执行测试
- 调用 API、下载资源、处理数据
- 操作 Git、部署代码、管理进程
一个能执行 shell 脚本的 Agent,理论上能做任何程序员能做的事。
但粗粒度不够
纯 shell 有个问题:它太底层了。让 Agent 用 sed 做文本替换,经常会因为转义字符、正则表达式的边界情况而翻车。
所以更好的做法是提供多层次的行动能力:
| 层次 | 工具 | 适用场景 |
|---|---|---|
| 精细操作 | 文件读写、搜索替换 | 修改代码、更新配置 |
| 中等操作 | 浏览器交互(点击、填写、导航) | Web 操作、测试验证 |
| 粗粒度操作 | Shell 脚本 | 构建、部署、系统管理 |
精细操作减少出错概率,粗粒度操作保证灵活性。两者结合,Agent 才能既稳又快。
一个真实的例子
我让 Agent 帮我搭这个博客的时候,它的”手”是这样协作的:
- 写文件(精细操作):创建 Markdown 文章、修改配置文件
- 执行脚本(粗粒度):
hexo generate构建、git push部署 - 浏览器操作(中等操作):打开部署后的页面,检查渲染效果
- 搜索替换(精细操作):发现 CSS 问题后,精准修改样式文件
整个流程它自己跑完,我只需要最后刷新页面看效果。
眼手协调:感知-决策-行动的闭环
眼和手单独存在没有意义,关键是它们要形成闭环。
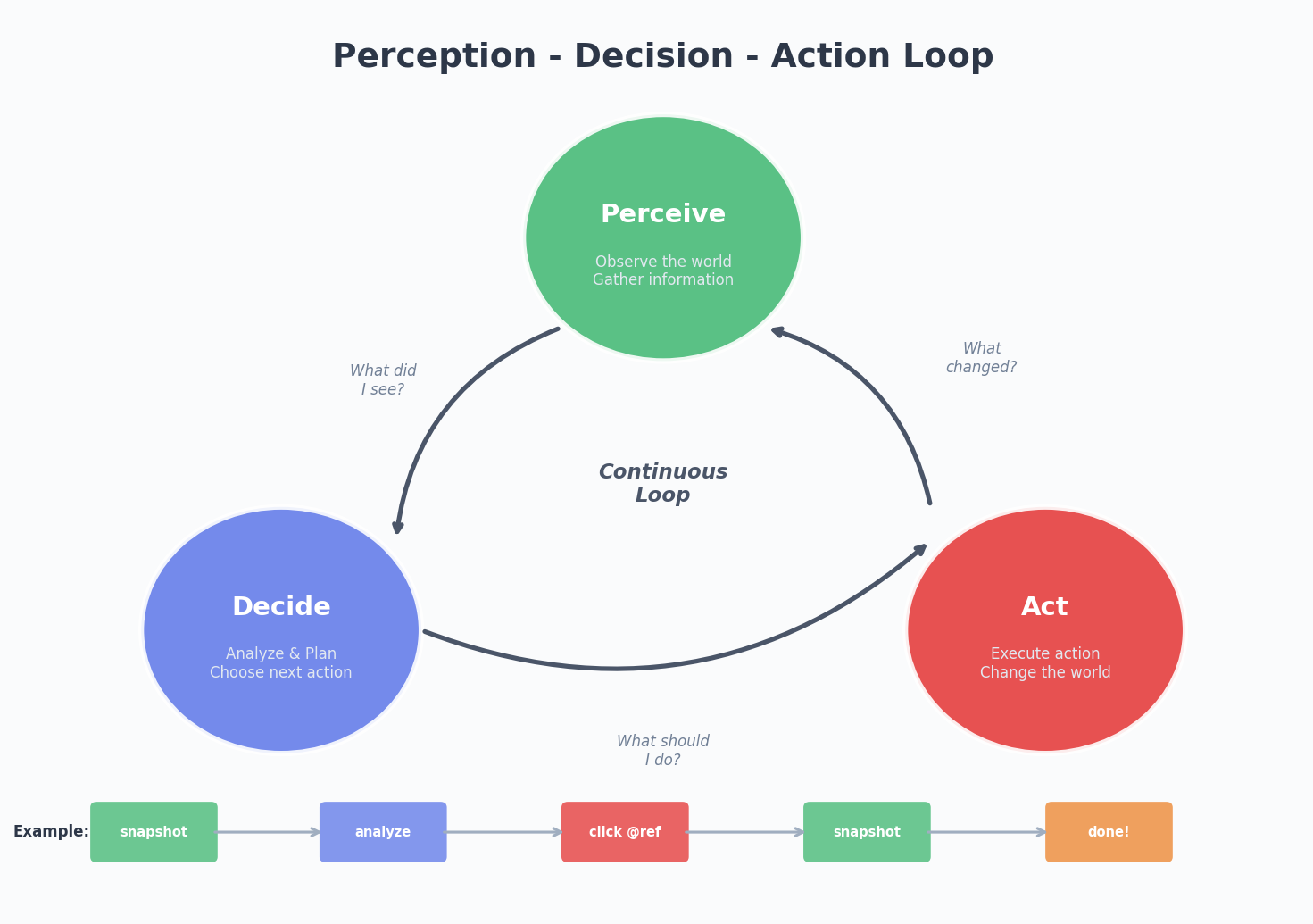
1 | 感知(看到了什么)→ 决策(应该做什么)→ 行动(去做)→ 感知(做完后世界变了吗)→ ... |
这个闭环听起来简单,但实现起来有很多细节:
1. 行动后必须验证
Agent 执行了一个操作后,不能就假设成功了。它需要回头看一眼:
- 改了代码?跑一下测试。
- 部署了网站?打开浏览器看看。
- 安装了依赖?检查
node_modules是否存在。
不验证的行动是危险的。 这就像闭着眼睛过马路——你迈出了步子,但不知道有没有车。
2. 错误是信息,不是终点
当 Agent 执行脚本报错时,错误信息本身就是最有价值的感知输入。一个好的 Agent 会:
- 读取错误信息
- 分析原因
- 调整方案
- 重新执行
而不是直接告诉你”执行失败了,请手动处理”。
3. 知道什么时候该停
闭环不能无限转下去。Agent 需要判断:
- 任务完成了吗?
- 是不是陷入了死循环?
- 是不是应该问用户确认?
这是一种元认知能力——不只是做事,还要知道自己在做什么、做得怎么样。
当前方案的局限
说了这么多好处,也得聊聊现实中的坑。
安全边界模糊
Agent 能执行 shell 脚本,意味着它理论上能 rm -rf /。虽然没有哪个正常的 Agent 会这么做,但权限控制是一个必须认真对待的问题。
目前的做法通常是:
- 限制工作目录
- 禁止危险命令
- 关键操作需要人工确认
但这些都是打补丁。更根本的解决方案可能是沙箱化执行环境——Agent 在一个隔离的容器里操作,即使出错也不会影响宿主系统。
感知带宽有限
即使有了浏览器和文件系统,Agent 的感知带宽仍然远低于人类。人类一眼就能看出”这个页面布局不对”,Agent 需要解析整个 DOM 树才能得出类似的判断。
多模态模型在进步,但还没到”一眼看懂”的程度。 目前的最佳实践是结构化感知(Snapshot)和视觉感知(截图)结合使用。
长任务的上下文丢失
一个复杂任务可能需要几十步操作。随着步骤增多,早期的感知信息会被挤出上下文窗口。Agent 可能忘了自己三步之前看到了什么。
这又回到了记忆管理的问题——眼睛看到的东西,也需要被记住。
未来:更丰富的感知和更精准的行动
我觉得 Agent 的眼和手会沿着几个方向进化:
感知侧
- 实时视觉理解:不只是截图,而是像人一样”看”屏幕,理解布局、颜色、动画
- 多源信息融合:同时处理代码、日志、浏览器、数据库等多个信息源
- 主动探索:不等你告诉它看哪里,自己去翻文件、查日志、搜文档
行动侧
- 更精细的操作:像人一样操作 IDE——重构代码、运行调试器、设置断点
- 跨系统协作:同时操作多个服务、多个环境、多个工具链
- 物理世界交互:通过 IoT 设备、机器人接口,从数字世界延伸到物理世界
协调侧
- 自适应策略:根据任务复杂度自动选择感知精度和行动粒度
- 并行操作:同时执行多个子任务,而不是串行等待
- 协作能力:多个 Agent 分工合作,一个负责前端,一个负责后端,一个负责测试
写在最后
回到最初的问题:如何让 Agent 长出自己的眼和手?
技术上,答案是给它接入浏览器、文件系统、终端、API 等工具。但更深层的答案是:让它形成感知-决策-行动的闭环,并且在这个闭环中不断学习和改进。
一个只会说的 Agent 是顾问。一个能看能做的 Agent 是同事。一个能看、能做、还能从错误中学习的 Agent,才是真正的伙伴。
我们正在从”顾问时代”走向”同事时代”。这条路还很长,但每一步都让人兴奋。
这篇文章的搭建、部署、调试过程,全部由一个有眼有手的 Agent 完成。它看到了页面白屏,自己查了原因,改了配置,重新部署。这就是眼和手的力量。
如果你也在探索 Agent 的能力边界,欢迎在 Twitter 上找我聊。
 微信
微信- 支付宝

