Agent Memory Management in the Era of Super Large Models
A Real Scenario
I’ve been using an AI Agent recently to help me with all sorts of tasks — building a blog, writing a component library, tweaking styles, deploying code. After a few days, I noticed something interesting:
It remembers that I prefer pnpm, knows my GitHub username, remembers I said “get rid of the top banner,” and even knows my WeChat ID.
But sometimes it makes rookie mistakes — like reverting a bug fix I’d already confirmed, or forgetting a preference I’d explicitly stated.
This got me thinking seriously about a question: In an era where model context windows are already hundreds of thousands of tokens, how should Agent memory management actually work?
Is a Bigger Context Window Enough?
Many people have an intuition: context windows are getting huge — 128K, 200K, even 1M tokens. Can’t we just stuff all the history in there and call it a day?
The answer is: not even close.
Three reasons:
1. Cost Is a Hard Constraint
Even if a model supports 1M tokens of context, do you really want to fill it every single inference call? At current API pricing, a single million-token call might cost several dollars. An active Agent might run hundreds of inferences per day.
Do the math: if you max out 1M context every time, daily API costs could easily hit thousands of dollars. That’s unacceptable for individual developers and a massive cost pressure for enterprises.
2. Long Context ≠ Long Memory
This is something many people overlook. Models show significantly degraded information extraction from the middle portions of very long contexts — the so-called “Lost in the Middle” problem.
If you bury a conversation from three months ago at the 500K-token mark, the model will likely ignore it completely. A context window is a queue, not a database. You can’t expect a model to pinpoint critical information from massive text like a search engine.
3. Not Everything Is Worth Remembering
This is the most crucial point. The reason human memory is efficient isn’t because we remember everything — it’s because we’re good at forgetting.
You don’t need to remember the output of every git push, but you do need to remember “this project uses pnpm instead of npm because npm has cache permission issues.” The former is noise; the latter is knowledge.
Good memory management is essentially the art of forgetting.
Current Mainstream Agent Memory Approaches
The industry’s Agent memory management roughly breaks down into several layers:
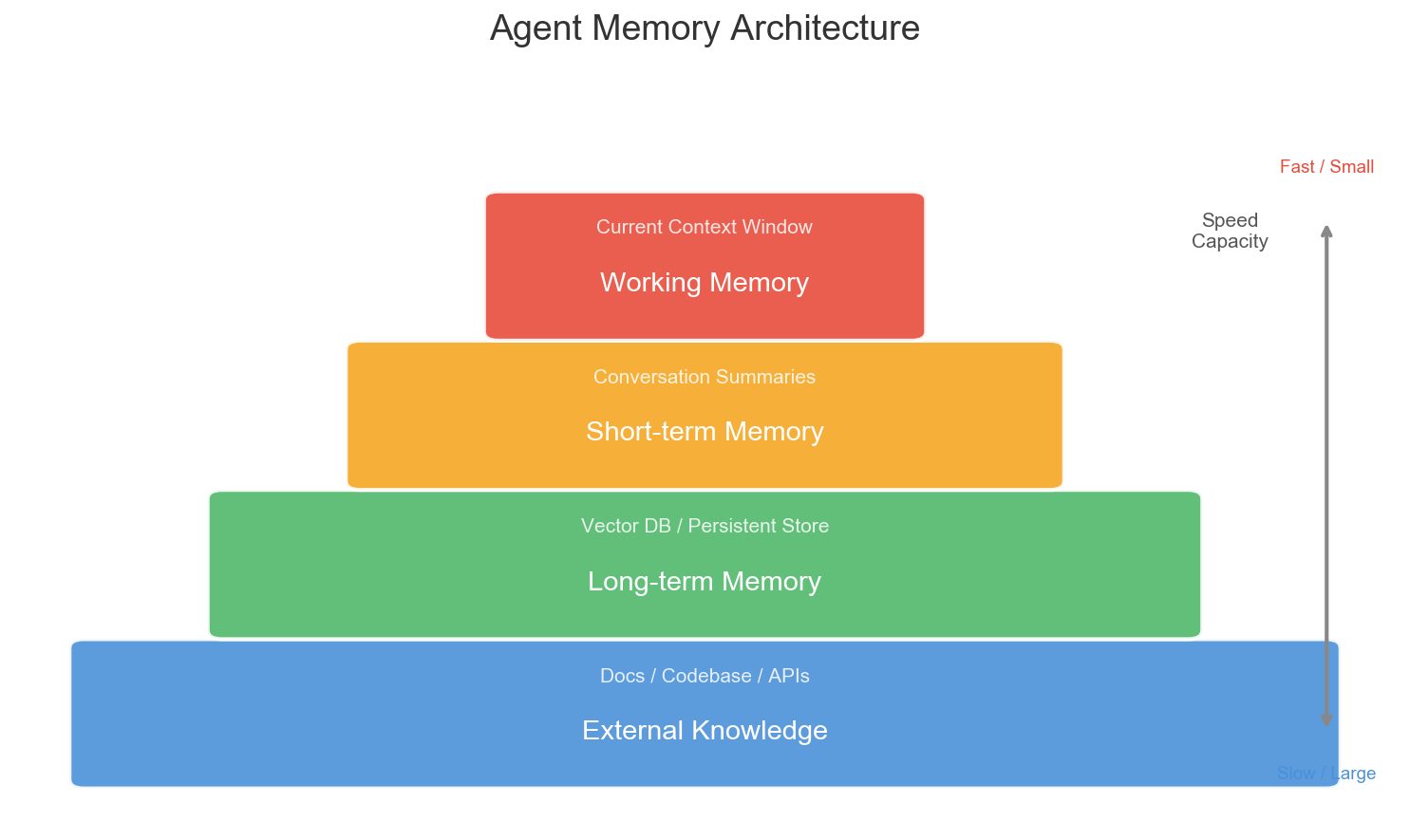
Working Memory
The current conversation context. What the model can directly “see.” Limited capacity, but fastest access and highest accuracy.
Human analogy: what you’re actively thinking about right now.
Short-term Memory
Summaries of recent conversation rounds. Usually auto-compressed by an LLM, retaining key information while discarding details.
Human analogy: you roughly remember what you did today, but the exact words of every conversation are already fuzzy.
Long-term Memory
Persistent information across sessions. Typically stored in vector databases, retrieved via embedding similarity.
Human analogy: you know a colleague’s habits, a project’s architectural decisions — knowledge accumulated over time.
External Knowledge
Documentation, codebases, API docs, etc. Agents access these on-demand through RAG (Retrieval-Augmented Generation).
Human analogy: you don’t memorize the entire manual, but you know where to look.
Key Problems I’ve Observed
Through hands-on Agent usage, I’ve identified several pain points with existing memory approaches:
Problem 1: Summaries Lose Critical Details
When an Agent compresses long conversations into summaries, it has to make trade-offs. But judging what’s important and what’s not is inherently difficult.
Example: I told my Agent “don’t add the /ideas/ prefix to image paths.” In a long debugging conversation, this might be just one line, but it’s a critical project rule. If it gets dropped during summarization, the same mistake will happen again.
Problem 2: Vector Retrieval Has Unstable Recall
Long-term memory typically relies on vector similarity search. But natural language semantics are fuzzy — “npm has permission issues” and “use pnpm instead of npm” are semantically related but expressed very differently. Critical information might be missed during retrieval.
Problem 3: Memory Lacks Structure
Most Agent memories are just piles of text fragments. But human memory is structured — we organize knowledge into concepts, rules, experiences, preferences, and other categories.
An Agent should know that “user prefers pnpm” is a preference rule, not just a sentence that appeared in some conversation.
My Vision: The Ideal Agent Memory System
Based on these observations, I believe future Agent memory systems should have several characteristics:
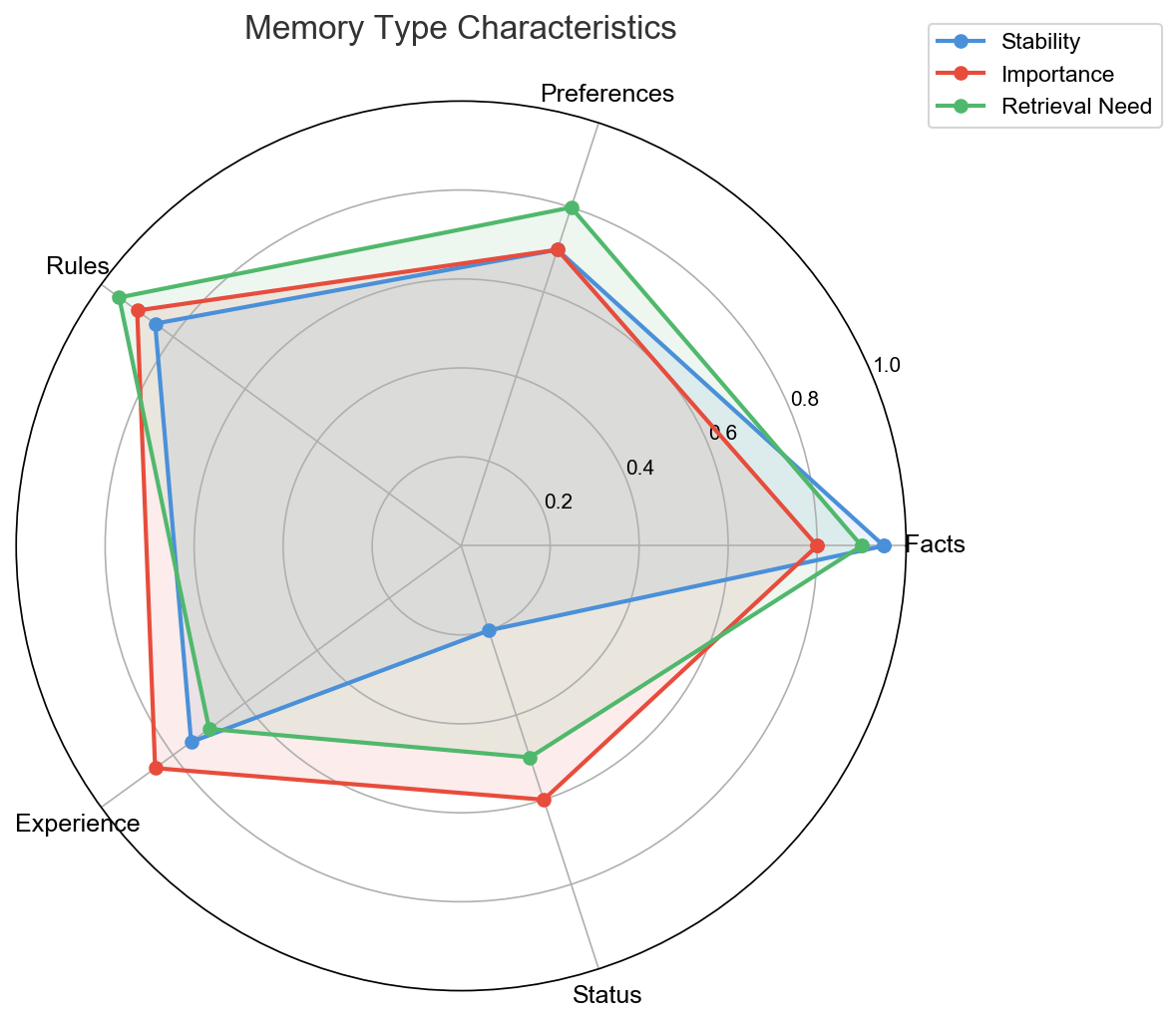
1. Layered + Categorized
Not a simple “short-term/long-term” binary, but categorized by information type:
| Type | Example | Characteristics |
|---|---|---|
| Facts | User’s GitHub username is hongqi-lgs | High certainty, rarely changes |
| Preferences | User likes headed browser mode | May change, but infrequently |
| Rules | Don’t add /ideas/ prefix to image paths | Project-level hard constraints |
| Lessons | npm has cache permission issues, use pnpm | Learned from mistakes |
| State | Currently developing the Switch component | Time-sensitive, will expire |
Different types of memory should have different storage strategies, retrieval weights, and expiration mechanisms.
2. Active Forgetting
Agents should be able to proactively clean up outdated information. Debugging logs from three months ago, details of resolved bugs, temporary intermediate states — these should all be gradually phased out.
Not deletion, but de-prioritization. Like human memory, information that’s rarely recalled gradually fades, but can still be retrieved if triggered.
3. Self-Correcting Memory
When an Agent discovers its memory contradicts reality, it should auto-update. If a user says “I’ve switched to npm now,” the Agent shouldn’t cling to the old “use pnpm” memory.
This requires a conflict detection and resolution mechanism — when new information contradicts old memory, prioritize the new and mark the old as “outdated.”
4. Explainable Memory
Users should be able to see what the Agent remembers, why it remembers it, and when it was stored. This isn’t just about transparency — it’s the foundation of trust.
If you don’t know what information an AI has stored about you, how can you trust it with important tasks?
A Bolder Idea
I’ve been mulling over a possibly ahead-of-its-time thought:
Future Agent memory shouldn’t follow a “store-retrieve” model, but a “grow-evolve” model.
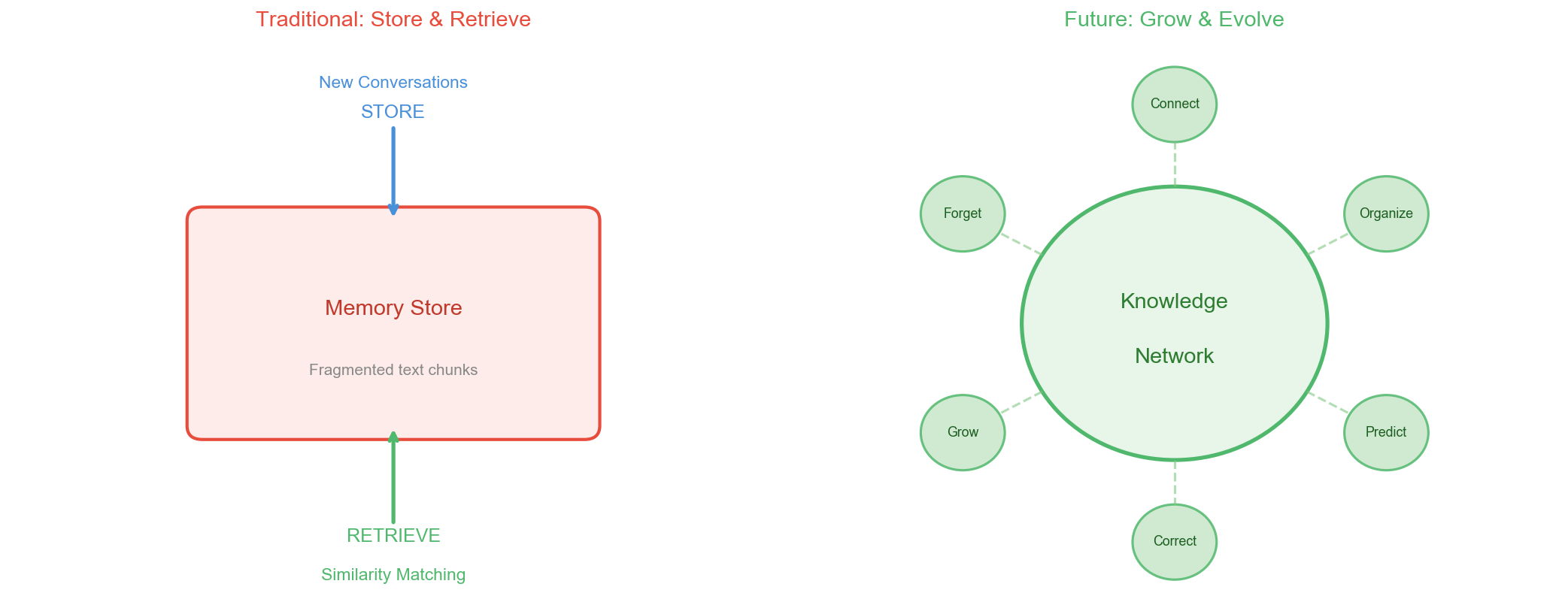
What do I mean?
Current memory systems are essentially databases: store it, query it. But human memory doesn’t work that way. Our memories get reorganized during sleep, different memory fragments get reconnected, forming new understanding.
Imagine: an Agent during “idle time” (when there’s no user interaction) automatically reviews its memories, organizes scattered experiences into systematic knowledge, discovers common patterns across different projects, and even proactively suggests optimizations.
This is no longer memory management — it’s knowledge evolution.
Of course, this requires solving many technical challenges — computational cost, hallucination control, knowledge consistency verification, and more. But I believe this is an important direction for Agent development.
Final Thoughts
We’re at a fascinating inflection point. Model capabilities are advancing rapidly, context windows keep expanding, but Agent memory management remains a largely unsolved problem.
No matter how large the context window gets, it only gives you a bigger workbench. True intelligence lies in knowing what to put on that workbench — and what to leave off.
As someone who works with Agents every day, I increasingly believe that memory management might be the key step in determining whether Agents evolve from “tools” into “partners.”
An assistant that can’t remember your preferences will always be a tool that needs constant re-training. An assistant that understands you, remembers you, and can even anticipate your needs — that’s a true partner.
We’re still on the journey, but the direction is clear.
If you’re also working on Agent-related projects, I’d love to connect. Find me on Twitter at @xiaosen_lu.
 微信
微信- 支付宝

