谈谈超级大模型时代的Agent记忆管理
一个真实的场景
最近我一直在用一个 AI Agent 帮我干活——搭博客、写组件库、调样式、部署代码。几天下来,我发现一个有意思的现象:
它记得我喜欢用 pnpm,记得我的 GitHub 用户名,记得我说过”顶部大色块不要了”,甚至记得我微信号是什么。
但有时候它又会犯一些低级错误,比如把已经修过的 bug 再改回去,或者忘了我之前明确说过的偏好。
这让我开始认真思考一个问题:在大模型上下文窗口已经动辄几十万 token 的今天,Agent 的记忆管理到底应该怎么做?
上下文窗口够大,就不需要记忆了吗?
很多人有一个直觉:模型的上下文窗口越来越大,128K、200K、甚至 1M token,是不是把所有历史对话塞进去就完事了?
答案是:远远不够。
原因有三个:
1. 成本问题是硬约束
即使模型支持 1M token 的上下文,你真的要每次推理都把所有历史塞进去吗?按照目前的 API 定价,一次百万 token 的推理调用,成本可能就是几块钱。一个活跃的 Agent 一天可能要推理几百次。
算一笔账:如果每次都用满 1M 上下文,一天的 API 费用可能就要上千。 这对个人开发者来说完全不可接受,对企业来说也是巨大的成本压力。
2. 长上下文 ≠ 长记忆
这是很多人忽略的一点。模型在处理超长上下文时,对中间部分的信息提取能力是显著下降的——这就是所谓的 “Lost in the Middle” 问题。
你把三个月前的一段对话塞在 50 万 token 的中间位置,模型大概率会”视而不见”。上下文窗口是个队列,不是数据库。你不能指望模型像搜索引擎一样精准地从海量文本中定位关键信息。
3. 不是所有信息都值得记住
这一点最关键。人类的记忆系统之所以高效,不是因为我们记住了一切,而是因为我们善于遗忘。
你不需要记住每一次 git push 的输出日志,但你需要记住”这个项目用 pnpm 不用 npm,因为 npm 有缓存权限问题”。前者是噪音,后者是知识。
好的记忆管理,本质上是一门遗忘的艺术。
当前主流的 Agent 记忆方案
目前业界的 Agent 记忆管理大致分几个层次:
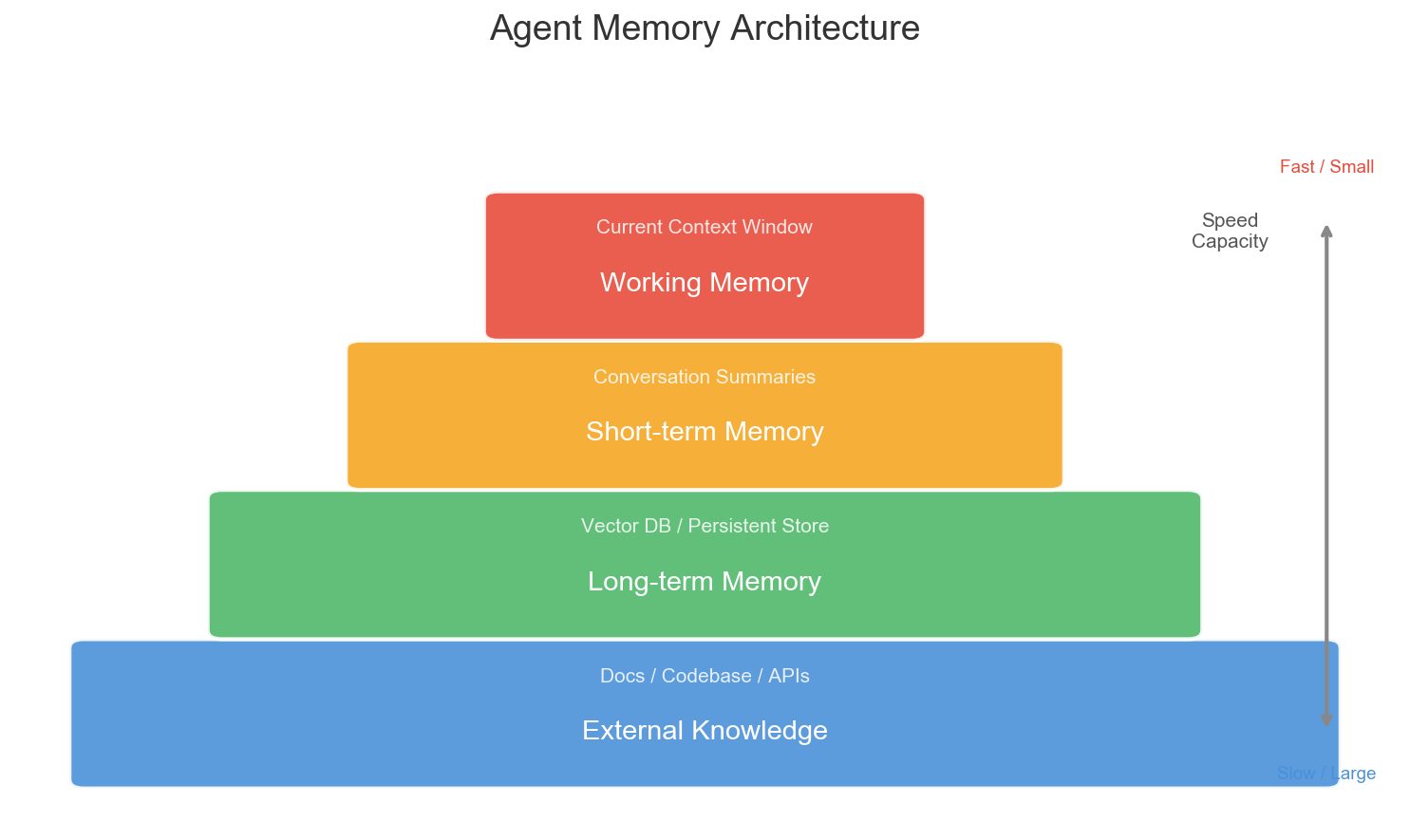
工作记忆(Working Memory)
就是当前对话的上下文。模型直接能”看到”的部分。容量有限,但访问速度最快、准确度最高。
类比人类:你正在思考的事情。
短期记忆(Short-term Memory)
最近几轮对话的摘要。通常通过 LLM 自动总结压缩,保留关键信息,丢弃细节。
类比人类:你今天做了什么,大致还记得,但具体每句话说了什么已经模糊了。
长期记忆(Long-term Memory)
跨会话持久化的信息。通常存储在向量数据库中,通过 embedding 检索相关内容。
类比人类:你知道某个同事的习惯、某个项目的架构决策——这些是长期积累的知识。
外部知识库(External Knowledge)
文档、代码库、API 文档等。Agent 通过 RAG(检索增强生成)按需获取。
类比人类:你不需要背下整本手册,但你知道去哪里查。
我观察到的几个关键问题
在实际使用 Agent 的过程中,我发现现有的记忆方案有几个痛点:
问题一:摘要会丢失关键细节
当 Agent 把长对话压缩成摘要时,它必须做取舍。但什么是重要的,什么是不重要的,这个判断本身就很难。
举个例子:我跟 Agent 说”图片路径不要加 /ideas/ 前缀”。这句话在一段很长的调试对话中可能只占一行,但它是一个关键的项目规则。如果摘要时被丢掉了,下次它又会犯同样的错误。
问题二:向量检索的召回率不稳定
长期记忆通常依赖向量相似度检索。但自然语言的语义是模糊的——“npm 有权限问题”和”用 pnpm 代替 npm”,语义上相关但表述差异很大。检索时可能漏掉关键信息。
问题三:记忆缺乏结构化
大多数 Agent 的记忆就是一堆文本片段。但人类的记忆是有结构的——我们会把知识组织成概念、规则、经验、偏好等不同类别。
一个 Agent 应该知道”用户偏好 pnpm”是一条偏好规则,而不只是某次对话中出现过的一句话。
我的思考:理想的 Agent 记忆系统
基于这些观察,我觉得未来的 Agent 记忆系统应该有几个特征:
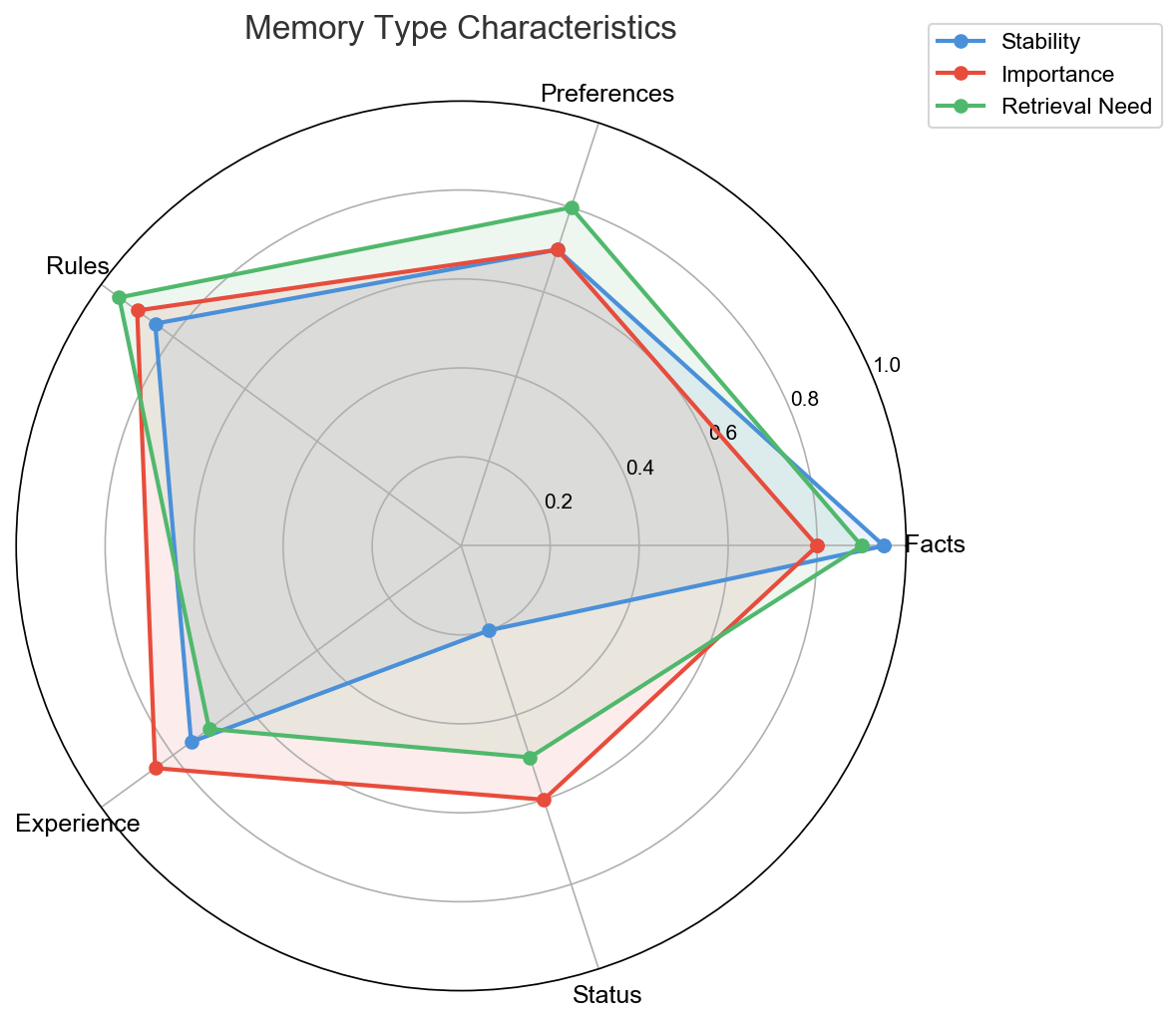
1. 分层 + 分类
不是简单的”短期/长期”二分法,而是按信息类型分类:
| 类型 | 示例 | 特征 |
|---|---|---|
| 事实 | 用户的 GitHub 用户名是 hongqi-lgs | 确定性高,几乎不变 |
| 偏好 | 用户喜欢 headed 模式的浏览器 | 可能变化,但变化频率低 |
| 规则 | 图片路径不加 /ideas/ 前缀 | 项目级别的硬约束 |
| 经验 | npm 有缓存权限问题,用 pnpm 绕过 | 从错误中学到的教训 |
| 状态 | 当前正在开发 Switch 组件 | 时效性强,会过期 |
不同类型的记忆,应该有不同的存储策略、检索权重和过期机制。
2. 主动遗忘
Agent 应该有能力主动清理过时的信息。三个月前的调试日志、已经解决的 bug 详情、临时的中间状态——这些都应该被逐步淘汰。
不是删除,而是降权。 就像人类的记忆一样,不常被提起的信息会逐渐模糊,但如果被触发,还是能想起来。
3. 记忆的自我修正
当 Agent 发现自己的记忆与现实矛盾时,应该能自动更新。比如用户说”我现在改用 npm 了”,Agent 不应该还抱着”用 pnpm”的旧记忆不放。
这需要一个冲突检测和解决机制——新信息和旧记忆矛盾时,以新信息为准,并标记旧记忆为”已过时”。
4. 可解释的记忆
用户应该能看到 Agent 记住了什么、为什么记住、什么时候记住的。这不仅是透明度的问题,也是信任的基础。
如果你不知道 AI 记住了你的什么信息,你怎么敢把重要的事情交给它?
一个更大胆的想法
我最近在想一个可能有点超前的观点:
未来的 Agent 记忆,可能不应该是”存储-检索”模式,而应该是”生长-进化”模式。
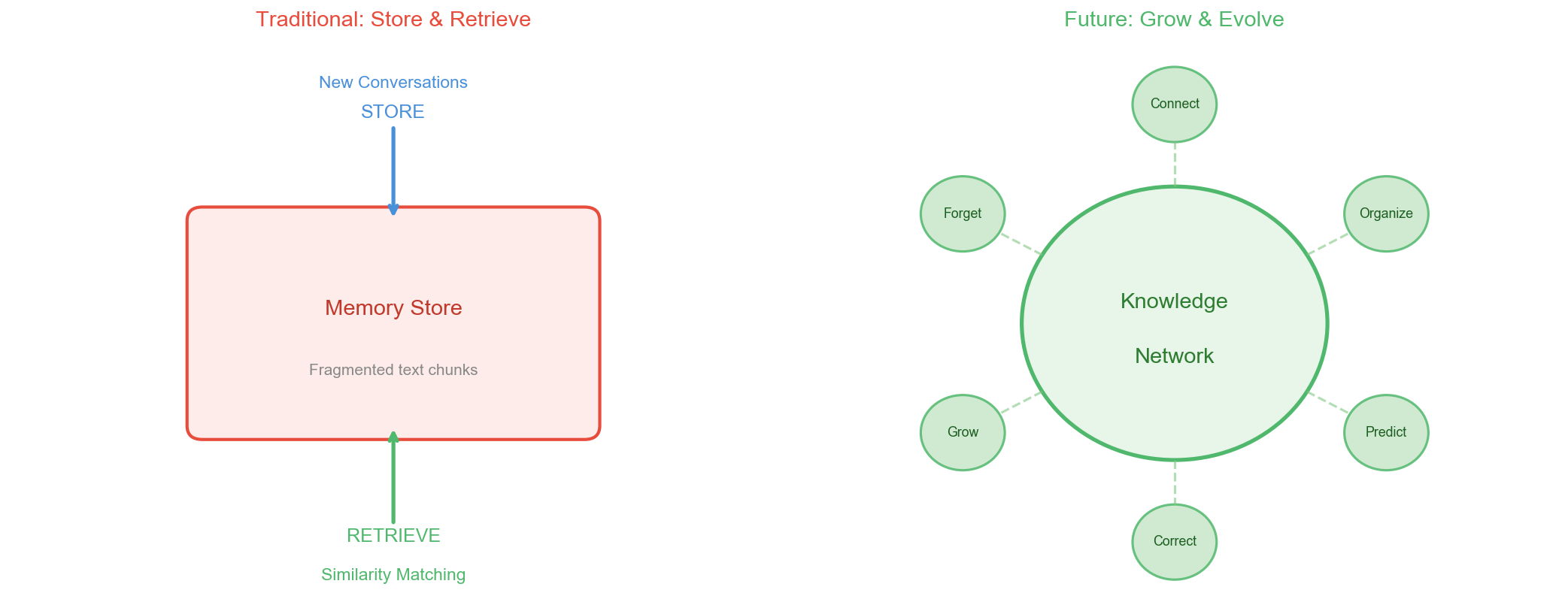
什么意思呢?
现在的记忆系统本质上是一个数据库:存进去,查出来。但人类的记忆不是这样工作的。我们的记忆会在睡眠中被重新整理,不同的记忆片段会被重新关联,形成新的理解。
想象一下:一个 Agent 在”空闲时间”(没有用户交互的时候),自动回顾自己的记忆,把零散的经验整理成系统的知识,发现不同项目之间的共性模式,甚至主动提出优化建议。
这不再是记忆管理,而是知识进化。
当然,这需要解决很多技术问题——计算成本、幻觉控制、知识一致性验证等等。但我相信这是 Agent 发展的一个重要方向。
写在最后
我们正处在一个有趣的时间节点。大模型的能力在飞速提升,上下文窗口在不断扩大,但 Agent 的记忆管理仍然是一个远未解决的问题。
上下文窗口再大,也只是给了你一个更大的工作台。真正的智能,在于知道工作台上该放什么、不该放什么。
作为一个每天都在和 Agent 打交道的人,我越来越觉得:记忆管理可能是决定 Agent 能否从”工具”进化为”伙伴”的关键一步。
一个记不住你偏好的助手,永远只是一个需要反复调教的工具。一个能理解你、记住你、甚至能预判你需求的助手,才是真正的伙伴。
我们还在路上,但方向已经清晰了。
如果你也在做 Agent 相关的工作,欢迎交流。我的 Twitter 是 @xiaosen_lu。
 微信
微信- 支付宝

