The Infrastructure of the AI Era
The Road Builders
There’s a saying I grew up hearing: if you want to get rich, build roads first.
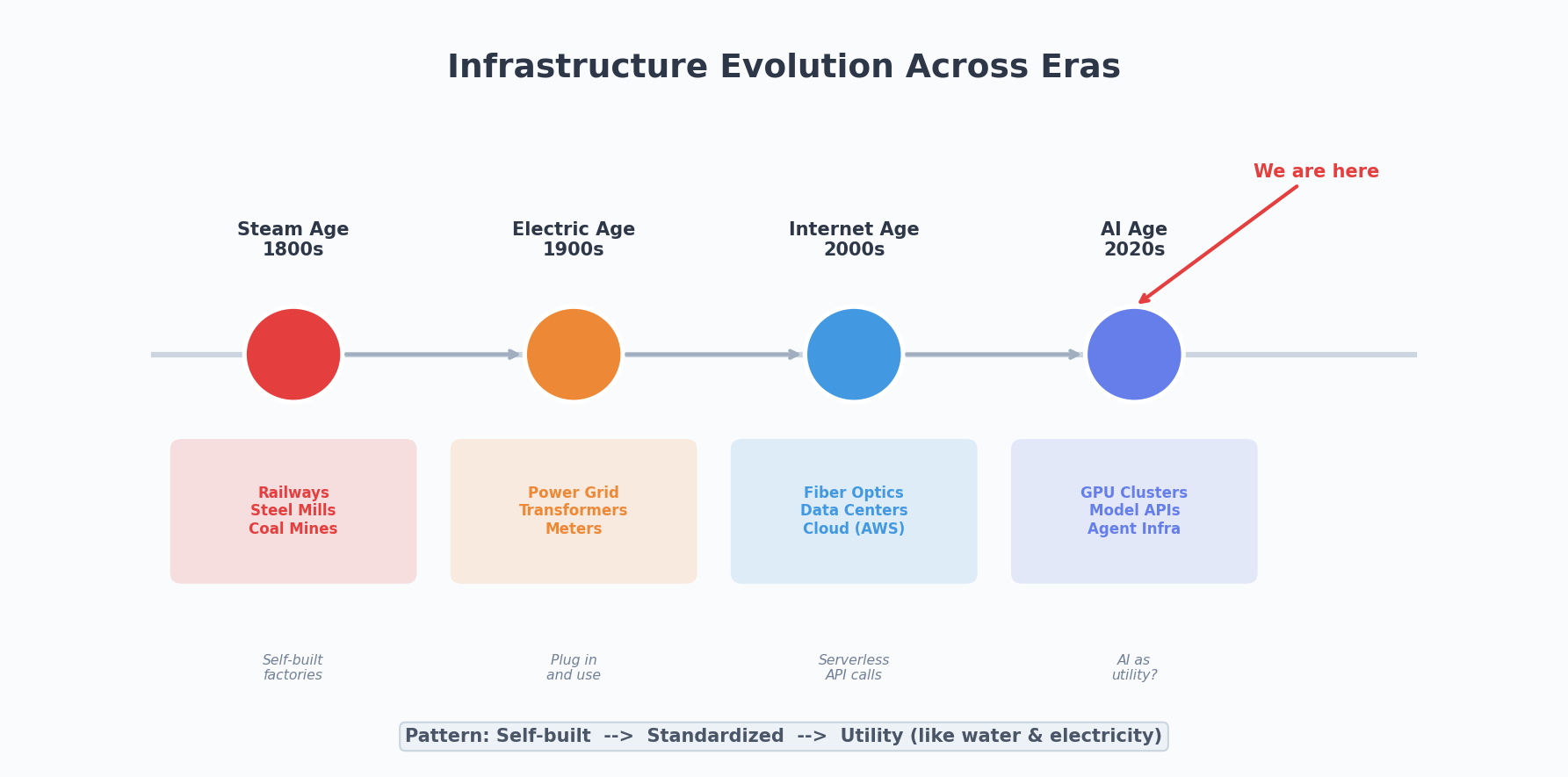
This applies to technology just as well. Every technological revolution is preceded by massive infrastructure buildout. The steam age built railways. The electrical age strung power grids. The internet age laid fiber optic cables and erected data centers. Infrastructure isn’t glamorous, but without it, even the best technology can’t run.
Now it’s AI’s turn.
Since GPT came along, everyone’s been talking about how smart the models are and what they can do. But few people seriously discuss: what roads do we need to build to make AI actually work?
That’s what this article is about — what AI-era infrastructure actually looks like.
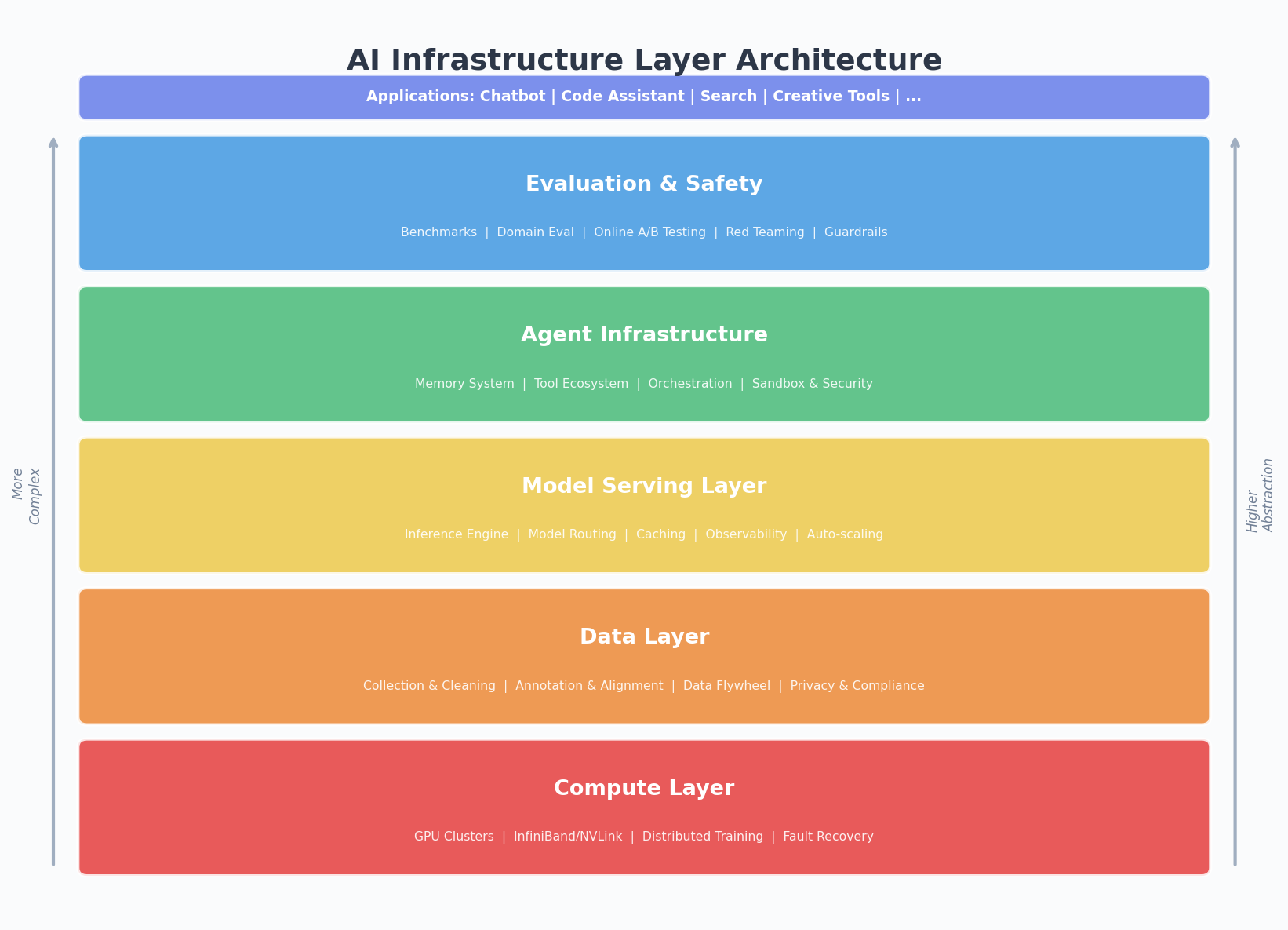
Compute: The Most Visible Layer
When people think of AI infrastructure, GPUs come to mind first. And yes, compute is the most visible and expensive layer. NVIDIA’s market cap tells the story.
But the compute story is far more complex than “buy more cards.”
Training a large model requires thousands of GPUs working in concert for months. Behind this lies distributed computing, high-speed interconnects (InfiniBand/NVLink), large-scale cluster scheduling, fault recovery… each one a hardcore engineering challenge. How many failures OpenAI’s cluster experienced during GPT-4 training, how many checkpoint recoveries they performed — outsiders can barely imagine.
The inference side presents entirely different challenges. Training is a one-time cost (albeit expensive), but inference is continuous — every user’s every conversation consumes compute. When your product has hundreds of millions of users, inference cost is the real heavyweight. That’s why everyone’s racing on inference optimization: quantization, distillation, speculative decoding, KV cache optimization…
But compute is just the tip of the iceberg. Just as the internet era needed more than servers — it needed CDNs, load balancers, databases — the AI era needs far more than GPUs.
Data: Scarcer Than Compute
There’s a pattern that’s been validated repeatedly: data quality determines a model’s ceiling; compute only determines how fast you approach it.
Public text on the internet has been scraped nearly dry. Every model company is struggling for high-quality data. You see seemingly absurd news — one company buying an entire publisher’s catalog, another hiring tens of thousands of annotators, another using its own model to generate synthetic training data.
Data infrastructure has several layers:
Collection and cleaning. Raw data is dirty, duplicated, biased. Turning it into usable training data requires an entire pipeline: deduplication, filtering, anonymization, formatting. This work isn’t glamorous, but it determines a model’s character.
Annotation and alignment. RLHF (Reinforcement Learning from Human Feedback) requires massive amounts of high-quality human preference data. Annotator quality directly affects a model’s “values.” This is a labor-intensive step and the most easily underestimated one.
Data flywheels. The truly powerful companies don’t just solve data once — they build data flywheels. Users generate data through the product, data improves the model, the model improves the product, the product attracts more users. ChatGPT’s data flywheel is already spinning, and this is the hardest moat for newcomers to cross.
Model Serving: From Lab to Production
Training a good model is just the beginning. Turning it into a stable, efficient, scalable service is another massive engineering effort.
Several key challenges here:
Inference engines. vLLM, TensorRT-LLM, SGLang… these frameworks make the same GPUs serve more requests. Continuous batching, PagedAttention, speculative decoding — each optimization can multiply throughput several times over.
Model routing. Not every request needs the largest model. Answering a simple greeting with GPT-4 is wasteful. Smart routing systems dispatch requests to appropriate models based on complexity — simple ones to small models, complex ones to large models. Saves money and improves speed.
Caching and precomputation. Many requests are similar. Semantic caching can return answers for similar questions directly, skipping inference. Prompt prefix caching can reuse KV caches, reducing redundant computation.
Observability. Models aren’t deterministic systems — the same input can produce different outputs. You need to monitor latency, throughput, error rates, and also output quality — hallucinations, harmful content, deviation from expectations. This is far more complex than traditional APM.
Agent Infrastructure: The Underestimated New Frontier
If large models are the AI era’s “engines,” then Agents are the “vehicles.” And Agents need their own infrastructure to run.
Memory systems. I discussed this in detail in my previous article. Agents need short-term memory (current conversation), working memory (current task context), and long-term memory (user preferences and historical knowledge). Most Agent memory systems today are primitive — either stuffing everything into the context window or using RAG retrieval. The future demands more elegant memory architectures.
Tool ecosystems. An Agent’s capabilities depend on what tools it can invoke. Browsers, code executors, file systems, API calls… each tool needs standardized interfaces, permission controls, error handling. MCP (Model Context Protocol) is attempting to solve this, but it’s still very early.
Orchestration frameworks. Complex tasks require multiple Agents collaborating, or a single Agent executing multi-step workflows. LangChain, CrewAI, AutoGen are all working on this, but honestly, current orchestration frameworks are still rough. The real challenge isn’t “how to chain things together” but “what happens when things go wrong” — retry, rollback, human intervention, partial recovery. Problems already solved in traditional workflow engines need to be re-solved in the Agent domain.
Sandboxing and security. Agents can execute code, access file systems, operate browsers — meaning they have the power to cause damage. You need sandboxes to limit their capabilities, audit logs to track their actions, human approval mechanisms to intercept high-risk operations.
Evaluation: AI’s Quality Control System
Traditional software has unit tests, integration tests, stress tests. Evaluating AI systems is much harder because outputs are non-deterministic and the definition of “correct” itself is fuzzy.
But without an evaluation system, you’re flying blind.
Benchmarks. MMLU, HumanEval, GSM8K… these public benchmarks are useful but limited — models might score well on benchmarks while performing poorly in real scenarios.
Domain evaluation. Every specific application needs its own evaluation set. Building a customer service bot? Evaluate with real customer service conversations. Building a code assistant? Evaluate with real coding tasks. Building high-quality domain evaluation sets is itself an infrastructure effort.
Online evaluation. A/B testing, user satisfaction, task completion rates… these metrics need continuous collection in production. And you need to distinguish between “the model got better” and “the prompt got better” and “the users changed” — far more complex than traditional A/B testing.
Red teaming. Specifically hunting for model vulnerabilities — can it be tricked into producing harmful content, can safety restrictions be bypassed, will it leak training data. This is an adversarial process requiring dedicated teams and tools.
Developer Perspective: A New Development Paradigm
As a developer, what I feel most deeply is: AI is changing the act of “writing code” itself.
The old development paradigm: write code → compile → test → deploy. Now there’s an additional dimension: write prompt → call model → evaluate → iterate. This isn’t replacement but addition. Your system has both deterministic code logic and non-deterministic model calls, and they need to work together.
This creates new infrastructure needs:
Prompt management. Prompts are the new era’s “code” — they need version control, A/B testing, gradual rollout. But most teams still hardcode prompts, requiring a full deployment to change one.
Model gateways. Your application might call multiple model providers simultaneously — OpenAI, Anthropic, locally deployed open-source models. You need a unified gateway to manage API keys, load balance, handle degradation, control costs.
Development tools. AI assistants in IDEs (Copilot, Cursor) are just the beginning. Future development tools will deeply integrate AI — not just code completion, but understanding your entire project, helping with architecture decisions, automatically writing tests, automatically doing code review.
Cost management. AI calls are billed per token, and prices vary enormously — GPT-4 costs dozens of times more than GPT-3.5. You need to monitor AI costs per feature, set budgets, find the balance between quality and cost.
The Endgame: AI Like Water and Electricity
Back to the original analogy.
When electricity first appeared, every factory built its own power station. Then came the power grid, and electricity became a public utility — you didn’t need to know how it was generated, just plug in and go.
The internet went through a similar process. From self-hosted servers to colocation, to cloud computing, to serverless — abstraction layers kept rising, and developers needed to worry about fewer and fewer low-level details.
The endgame of AI infrastructure should be the same.
Developers shouldn’t need to worry about GPU scheduling, model deployment, inference optimization. They should just say “I need a natural language understanding interface” or “I need an image analysis capability,” and the infrastructure layer handles everything automatically.
We’re still in the “build your own power station” phase. Every company is setting up their own GPU clusters, training their own models, building their own inference services. This is normal — early stages of new technology are always like this. But the trend is clear: standardization, service-ification, democratization.
In the next five years, AI infrastructure will undergo rapid standardization. Just as AWS defined the basic shape of cloud computing, some company will define the basic shape of AI infrastructure. By then, “using AI” will be as natural as “using a database” — you won’t need to be an AI expert to leverage AI capabilities in your product.
Final Thoughts
Every era’s infrastructure is unglamorous. Road builders aren’t as flashy as train riders. Data center builders aren’t as famous as app makers. But without them, trains can’t run and apps can’t load.
The AI era is the same. The spotlight falls on models and applications, but what truly determines how far this era goes is the unglamorous infrastructure underneath — data pipelines, inference engines, Agent frameworks, evaluation systems, development tools.
If you want to get rich, build roads first. This remains true in the AI era.
If you’re a developer, my advice is: don’t just chase model hype. Look at what’s happening in the infrastructure layer. That’s where the more durable opportunities and more solid value lie.
After all, when the tide goes out, what remains is infrastructure.
 微信
微信- 支付宝

