AI 时代的基建
修路的人
小时候听过一句话:要想富,先修路。
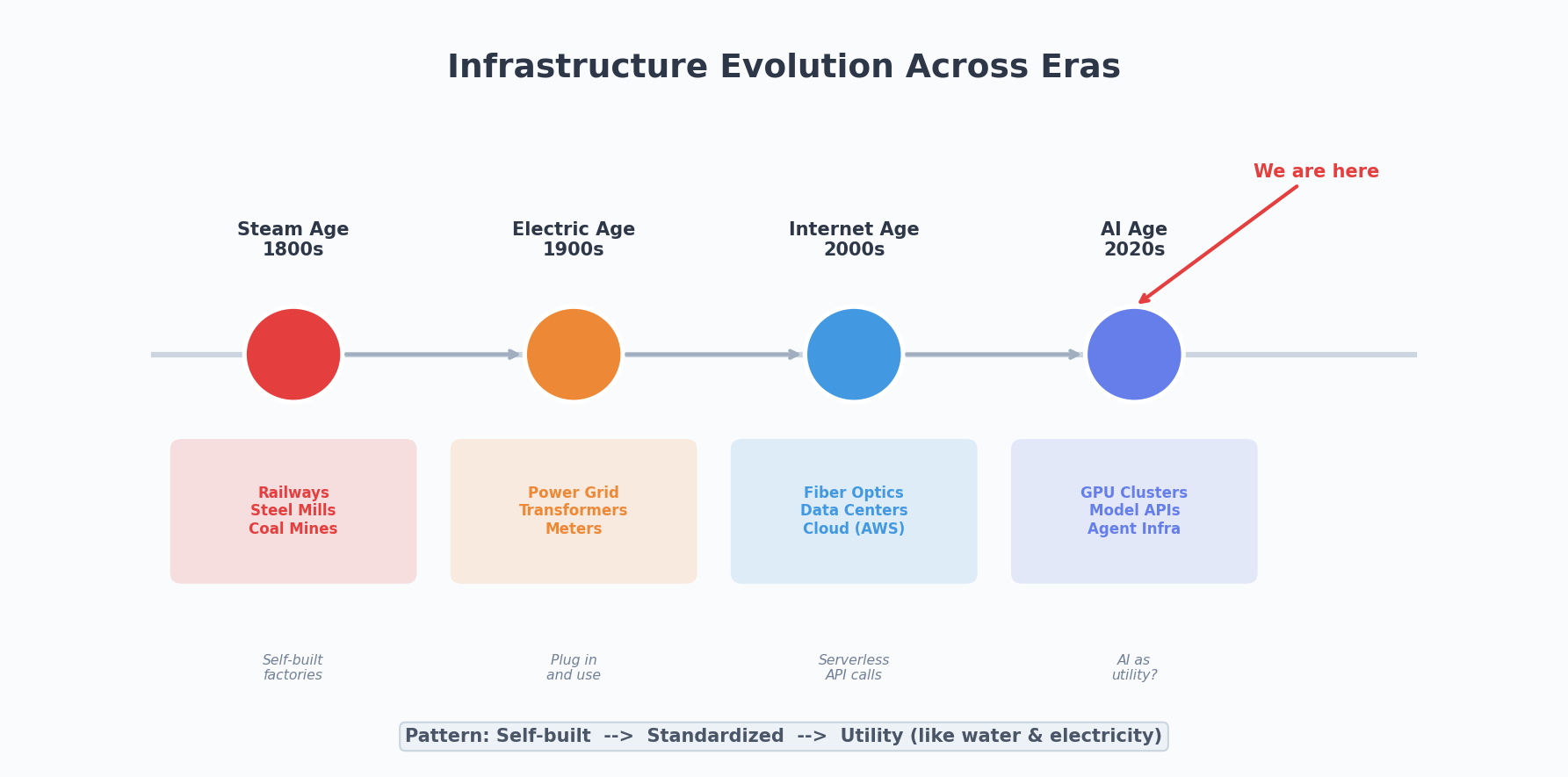
这话放到技术领域同样成立。每一次技术革命的爆发,背后都有一轮大规模的基础设施建设。蒸汽机时代修铁路,电气时代架电网,互联网时代铺光纤建数据中心。基建不性感,但没有它,再好的技术也跑不起来。
现在轮到 AI 了。
GPT 出来之后,所有人都在聊模型多聪明、能干什么。但很少有人认真聊过:要让 AI 真正跑起来,我们需要修什么路?
这篇文章想聊的就是这件事——AI 时代的基建,到底长什么样。
算力:最显眼的那一层
提到 AI 基建,大多数人第一反应是 GPU。没错,算力是最显眼、最烧钱的一层。英伟达的市值说明了一切。
但算力的故事远不止”买更多卡”这么简单。
训练一个大模型需要几千张 GPU 协同工作几个月,这背后是分布式计算、高速互联网络(InfiniBand/NVLink)、大规模集群调度、故障恢复……每一项都是硬核工程。OpenAI 训练 GPT-4 的集群出过多少次故障、做了多少次 checkpoint 恢复,外面的人很难想象。
而推理侧的挑战又完全不同。训练是一次性的(虽然很贵),但推理是持续的——每个用户的每次对话都在消耗算力。当你的产品有几亿用户时,推理成本才是真正的大头。所以你看到各家都在卷推理优化:量化、蒸馏、投机解码、KV Cache 优化……
但算力只是冰山一角。 就像互联网时代光有服务器不够,还需要 CDN、负载均衡、数据库一样,AI 时代光有 GPU 也远远不够。
数据:比算力更稀缺的资源
有一个被反复验证的规律:数据的质量决定了模型的上限,算力只决定你能多快逼近这个上限。
互联网上的公开文本已经被刮得差不多了。各家模型公司都在为高质量数据发愁。你会看到一些看似荒诞的新闻——某公司花大价钱买下了一整个出版社的版权,某公司雇了几万人做数据标注,某公司用自己的模型生成合成数据再拿来训练。
数据基建包含几个层面:
采集和清洗。 原始数据是脏的、重复的、有偏见的。把它变成可用的训练数据,需要一整套 pipeline:去重、过滤、脱敏、格式化。这些工作不光彩,但决定了模型的底色。
标注和对齐。 RLHF(基于人类反馈的强化学习)需要大量高质量的人类偏好数据。标注员的水平直接影响模型的”三观”。这是一个劳动密集型的环节,也是最容易被低估的环节。
数据飞轮。 真正厉害的公司不是一次性搞定数据,而是建立了数据飞轮——用户使用产品产生数据,数据反哺模型,模型改善产品,产品吸引更多用户。ChatGPT 的数据飞轮已经转起来了,这是后来者最难追赶的壁垒。
模型服务:从实验室到生产环境
训练出一个好模型只是开始。把它变成一个稳定、高效、可扩展的服务,又是另一个巨大的工程。
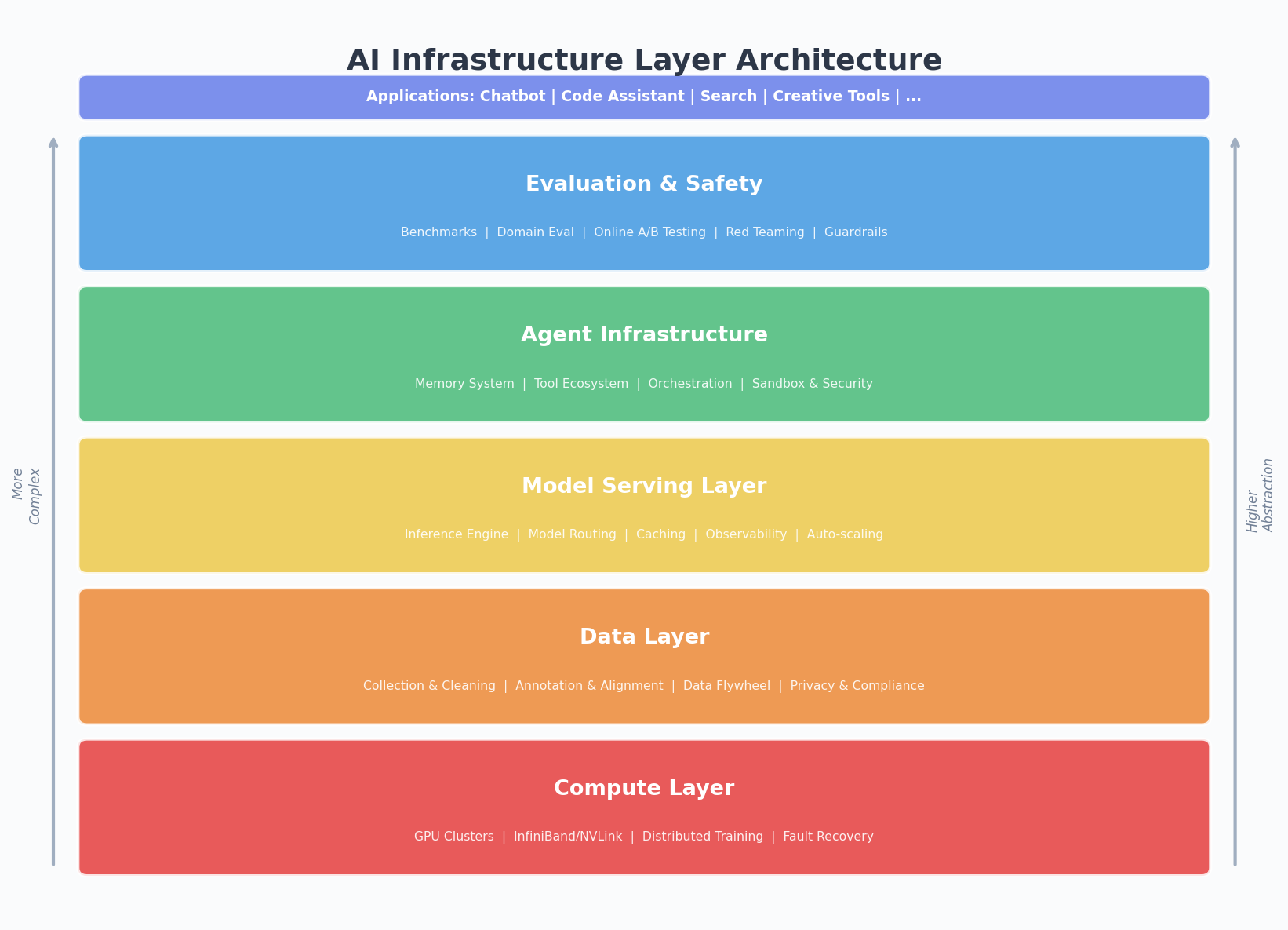
这里面有几个关键问题:
推理引擎。 vLLM、TensorRT-LLM、SGLang……这些推理框架做的事情是:让同样的 GPU 能服务更多的请求。Continuous batching、PagedAttention、Speculative decoding——每一个优化都能带来几倍的吞吐提升。
模型路由。 不是所有请求都需要最大的模型。一个简单的问候用 GPT-4 回答是浪费。智能路由系统根据请求的复杂度,把它分发到合适的模型——简单的用小模型,复杂的用大模型,既省钱又快。
缓存和预计算。 很多请求是相似的。语义缓存可以把相似问题的答案直接返回,省掉推理开销。Prompt 前缀缓存可以复用 KV Cache,减少重复计算。
可观测性。 模型不是确定性系统,同样的输入可能给出不同的输出。你需要监控延迟、吞吐、错误率,还需要监控输出质量——有没有幻觉、有没有有害内容、有没有偏离预期。这比传统的 APM 复杂得多。
Agent 基础设施:被低估的新战场
如果说大模型是 AI 时代的”发动机”,那 Agent 就是”整车”。而 Agent 要跑起来,需要自己的一套基建。
记忆系统。 我在上一篇文章里详细聊过这个。Agent 需要短期记忆(当前对话)、工作记忆(当前任务上下文)、长期记忆(用户偏好和历史知识)。现在大多数 Agent 的记忆还很原始——要么全塞进 context window,要么用 RAG 检索。未来需要更优雅的记忆架构。
工具生态。 Agent 的能力取决于它能调用什么工具。浏览器、代码执行器、文件系统、API 调用……每一个工具都需要标准化的接口、权限控制、错误处理。MCP(Model Context Protocol)在尝试解决这个问题,但还很早期。
编排框架。 复杂任务需要多个 Agent 协作,或者一个 Agent 执行多步骤的工作流。LangChain、CrewAI、AutoGen 都在做这件事,但说实话,现在的编排框架还很粗糙。真正的挑战不是”怎么串起来”,而是”出错了怎么办”——重试、回滚、人工介入、部分恢复,这些在传统工作流引擎里已经解决的问题,在 Agent 领域还需要重新解决。
沙箱和安全。 Agent 能执行代码、访问文件系统、操作浏览器——这意味着它有能力搞破坏。你需要沙箱来限制它的能力边界,需要审计日志来追踪它做了什么,需要人工审批机制来拦截高风险操作。
评估:AI 的”质检体系”
传统软件有单元测试、集成测试、压力测试。AI 系统的评估要难得多,因为输出是非确定性的,”正确”的定义本身就模糊。
但没有评估体系,你就是在盲人摸象。
基准测试。 MMLU、HumanEval、GSM8K……这些公开 benchmark 有用,但也有局限——模型可能在 benchmark 上刷分,在实际场景中拉胯。
领域评估。 每个具体应用都需要自己的评估集。你做客服机器人,就需要用真实的客服对话来评估;你做代码助手,就需要用真实的代码任务来评估。构建高质量的领域评估集,本身就是一项基建工作。
在线评估。 A/B 测试、用户满意度、任务完成率……这些指标需要在生产环境中持续收集。而且你需要区分”模型变好了”和”prompt 变好了”和”用户变了”——这比传统的 A/B 测试复杂得多。
红队测试。 专门找模型的漏洞——能不能被诱导说出有害内容、能不能被绕过安全限制、会不会泄露训练数据。这是一个攻防对抗的过程,需要专门的团队和工具。
开发者视角:新时代的开发范式
作为一个开发者,我感受最深的是:AI 正在改变”写代码”这件事本身。
以前的开发范式是:写代码 → 编译 → 测试 → 部署。现在多了一个维度:写 prompt → 调模型 → 评估 → 迭代。 这不是替代,而是叠加。你的系统里既有确定性的代码逻辑,也有非确定性的模型调用,两者需要协同工作。
这带来了新的基建需求:
Prompt 管理。 Prompt 是新时代的”代码”,需要版本控制、A/B 测试、灰度发布。但现在大多数团队还是把 prompt 硬编码在代码里,改一个 prompt 要发一次版。
模型网关。 你的应用可能同时调用多个模型提供商——OpenAI、Anthropic、本地部署的开源模型。你需要一个统一的网关来管理 API key、做负载均衡、处理降级、控制成本。
开发工具。 IDE 里的 AI 助手(Copilot、Cursor)只是开始。未来的开发工具会深度集成 AI——不只是补全代码,而是理解你的整个项目、帮你做架构决策、自动写测试、自动做 code review。
成本管理。 AI 调用是按 token 计费的,而且价格差异巨大——GPT-4 的价格是 GPT-3.5 的几十倍。你需要监控每个功能的 AI 成本,做预算控制,在质量和成本之间找平衡。
终局:像水电一样的 AI
回到最开始的类比。
电力刚出现的时候,每个工厂都自己建发电站。后来有了电网,电变成了公共服务——你不需要知道电是怎么发的,插上插头就能用。
互联网也经历了类似的过程。从自建机房到托管,到云计算,到 Serverless——抽象层越来越高,开发者需要关心的底层细节越来越少。
AI 基建的终局,也应该是这样。
开发者不需要关心 GPU 调度、模型部署、推理优化。他只需要说”我需要一个能理解自然语言的接口”或者”我需要一个能分析图片的能力”,基建层自动搞定一切。
我们现在还在”自建发电站”的阶段。各家公司都在自己搭 GPU 集群、自己训模型、自己建推理服务。这很正常——新技术的早期总是这样。但趋势是清晰的:标准化、服务化、平民化。
未来五年,AI 基建会经历一轮快速的标准化。就像 AWS 定义了云计算的基本形态一样,会有公司定义 AI 基建的基本形态。到那时候,”用 AI”会像”用数据库”一样自然——你不需要成为 AI 专家,就能在你的产品里用上 AI 能力。
写在最后
每个时代的基建都不性感。修铁路的人不如坐火车的人光鲜,建数据中心的人不如做 App 的人出名。但没有他们,火车跑不起来,App 也打不开。
AI 时代也一样。聚光灯打在模型和应用上,但真正决定这个时代能走多远的,是底下那些不起眼的基建——数据管道、推理引擎、Agent 框架、评估体系、开发工具。
要想富,先修路。这句话,在 AI 时代依然成立。
如果你是一个开发者,我的建议是:不要只追模型的热点,也看看基建层在发生什么。那里有更持久的机会,也有更扎实的价值。
毕竟,潮水退去之后,留下来的是基础设施。
 微信
微信- 支付宝

